
Benchmarking API latency of embedding providers (and why you should always cache your embeddings)
We measured the API latency of four major embedding providers—OpenAI, Cohere, Google, and Jina. We found is that the convenience of API integration can come at a cost if performance matters to you.

What Are Embeddings?
(Feel free to skip this section if you're already familiar with embeddings.)
If you're building a RAG or search application, at some point you'll need to calculate similarity between a search query and a set of documents.
In traditional lexical search, this similarity is often based on BM25, which still works great for exact keyword matches. For example, if a user searches for “nike airmax,” they probably want documents that include both of those exact terms.
But for those “I don’t know exactly what I’m looking for” queries—where the right keywords aren't obvious—you need to go beyond keywords and compare based on the semantics of the text.
That’s where embedding-based similarity comes in. Embeddings transform text into vectors in a high-dimensional space, where semantically similar pieces of text end up close to each other.

The advantage over using LLMs directly for RAG (e.g. dumping all documents into a context window) is that embeddings for documents can be precomputed and stored. This makes searching through 1M (or even 1B!) documents surprisingly cheap and efficient.
The only thing you need to embed at query time is... the query. And that’s where latency starts to matter.
Why latency matters
As we’re building a Yet Another Search Engine © with Nixiesearch, we’ve added inference capabilities directly into the search engine. Initially, Nixiesearch only supported local ONNX-based embedding inference.

In version 0.5, we added support for API-based embedding providers like OpenAI and Cohere. But from the start, this felt like the software equivalent of putting a shotgun on the wall—just waiting for a user to accidentally pull the trigger while pointing at the foot.
The questions were obvious:
How reliable are these APIs?
What latency cost are we paying for plug-and-play integration?

You might say, “But OpenAI doesn’t publish their latency stats.” True. But if they won’t, we will.
Experiment setup
We built a basic API scraper to benchmark major cloud-based embedding providers:
OpenAI: text-embedding-3-small and text-embedding-3-large models.
Cohere: the embed-english-v3.0 model.
Google Vertex AI: text-embedding-005 model.
Jina.ai: jina-embeddings-v3 model.
We also wanted to include mixedbread, but they pivoted to enterprise search and shut down their embedding API. Oh, the irony.
For each provider, we selected their latest and most powerful model. Input data came from random samples of queries and documents from the MSMARCO dataset. We sent an API request every 5 seconds and logged the results continuously for one week.
The scraper was written in Scala 3 (yes, with all the monads you remember from your favorite category theory book) and deployed in AWS us-east-1, the most common cloud region out there. Most embedding APIs are fronted by Cloudflare-style load balancers, so you never really know where the traffic ends up. OpenAI and Google claim to have points of presence in major regions, so us-east-1 was a safe bet.
Raw logs are available on Hugging Face: hf.co/datasets/nixiesearch/embed-api-latency
Are API embedding providers slow?
In a word: yes.

With 90th percentile latencies around 500ms, and 99th percentile spikes up to 5 seconds, this is not the kind of performance you want on the critical path of a search query.

And it’s not just OpenAI. We found that:
Cohere and Google Vertex AI generally have lower median latency than OpenAI, but with more volatility. On 2025-03-25, Google spiked to 3 seconds.
Jina AI consistently had the slowest latency across the board, even though their service status page claimed “100% operational” state.
We wondered if latency correlated with document length. Maybe longer texts took longer to process?

Nope. After tracking token counts and plotting median latency vs. token length, we ended up with the flattest dependency graph you’ve ever seen.
What does that suggest? That providers aren’t processing requests immediately—they’re batching them (at least we guess so). Each provider appears to have its own batching window:
OpenAI and Jina: ~300ms
Cohere: ~100ms
Google: ~50ms
This difference in batching explains most of the latency variation between providers.
But are these APIs reliable?
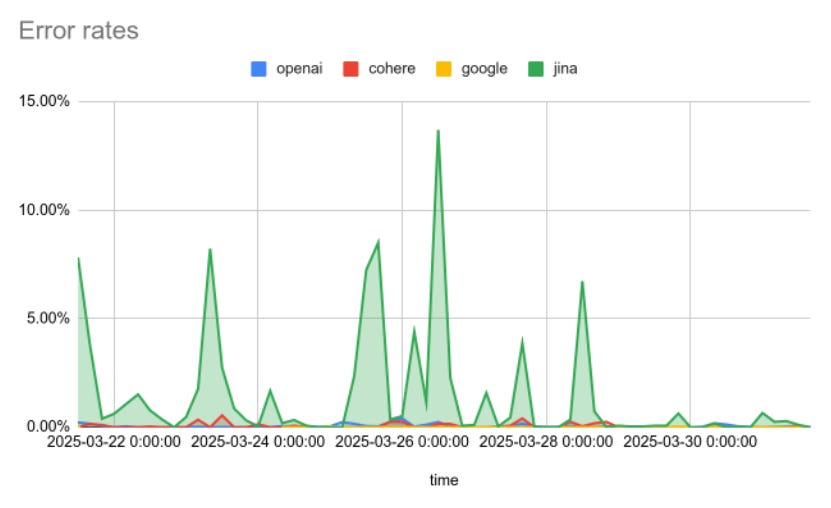
To our knowledge, none of these public embedding APIs offer an SLA if you’re not a large corporation. And the error rates we observed show there's a big room for improvement:
OpenAI: 0.05%
Google Vertex AI: 0.002%
Cohere: 0.06%
Jina AI: 1.45%
At first glance, 0.05% seems small. But it still means one out of every 2,000 requests fails. That may be acceptable for hobby projects, but for production systems? It’s risky.
So, what should you do?
We discovered that water is wet, sun is bright, and API-based embedding models are slow and unreliable. But what should you do as an application developer?
Cache your embeddings. If “pizza” is your most common search query, there’s no reason to recompute its embedding on every request. Cache hot queries.

And the second option is to prefer local embedding inference to API calls. API calls are great for vibe coding when your only goal is to have fun in the process. If you care about latency, you should seriously consider running your own embeddings.

Yes, but “computing embeddings on CPU is slow and you need an expensive cloud GPU for that” - you might answer.
Turns out, that’s no longer true. With QInt8 quantization, you can run a 500M parameter e5-large-v2 ONNX model on a CPU in just 10ms—which is way faster than hitting a cloud API.

Final words
Embedding APIs are super convenient—until they’re not. If you're just playing around or building a prototype, they’re great. But once you start caring about real-world performance, latency, and reliability, it’s a different story.
The takeaway? Always cache what you can, and seriously consider running your own models if you’re building anything production-grade. Local inference is faster, more predictable, and often cheaper than you'd think.
At the end of the day, fast search feels like magic—and nobody wants to wait five seconds for magic to happen.
The raw request logs are available on HuggingFace: hf.co/datasets/nixiesearch/embed-api-latency . You can also check out the scraper code on GitHub: github.com/nixiesearch/embed-api-benchmark