
Benchmarking SlateDB vs. RocksDB
I compared the raw read/write performance of SlateDB, a Rust-based embedded key-value database, against the industry-standard RocksDB in a "hot data" setup. And it's not that bad.

Disclaimer: this article is 99% human-written.
What’s special about SlateDB?
SlateDB is an embedded key-value database written in Rust, but with one big twist: it’s designed around block storage APIs like AWS S3.
Unlike RocksDB, which was built in the pre-cloud era, SlateDB supports tiered storage:
Hot data is cached in RAM or on a locally attached NVMe drive. Reads are super fast, but the hardware can get expensive.
Cold data lives on S3. Access is slower, but storage is significantly cheaper.
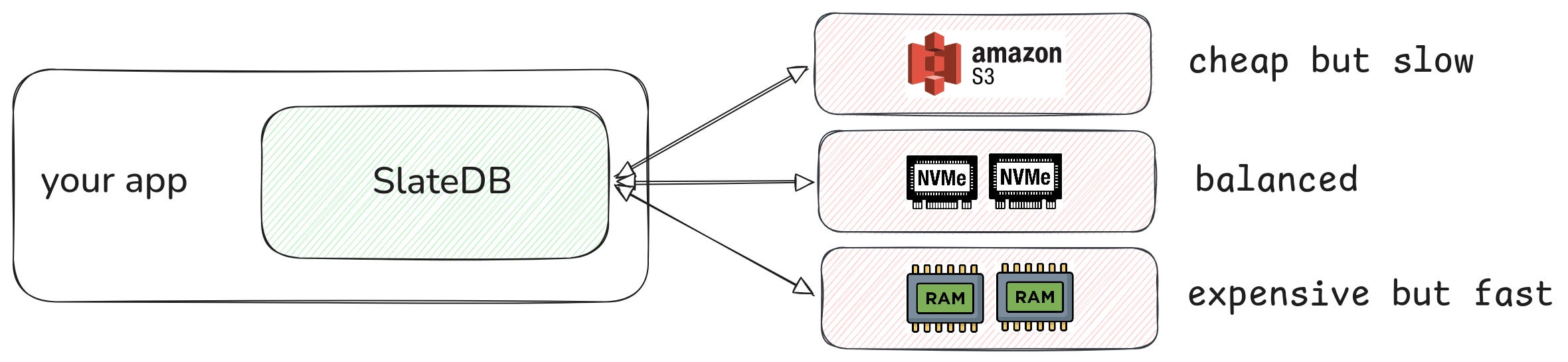
Beyond cost, this kind of tiered storage makes your embedded database almost stateless: S3 becomes the source of truth. So if your server crashes (say, because a drone hits your AWS availability zone) you can restart the app somewhere else and get your data back online.
Why do I care?
I’m building MurrDB, a caching server for AI/ML workloads: think Redis, but designed for batch reads and writes.
The original plan was to use RocksDB as the storage layer, then later build SST file replication on top of it to sync data through S3.

The main upside: RocksDB is fast and extremely stable.
The main downside: bolting S3-based replication onto a database that was never designed for it sounds painful.
Since Murrdb is also written in Rust, SlateDB looks like a very tempting alternative. Replication and consensus are hard even for experienced engineers, and I’m definitely not claiming to be one yet.
But that leaves the big question: How fast is SlateDB when everything is local and the comparison is as apples-to-apples as possible?
Methodology
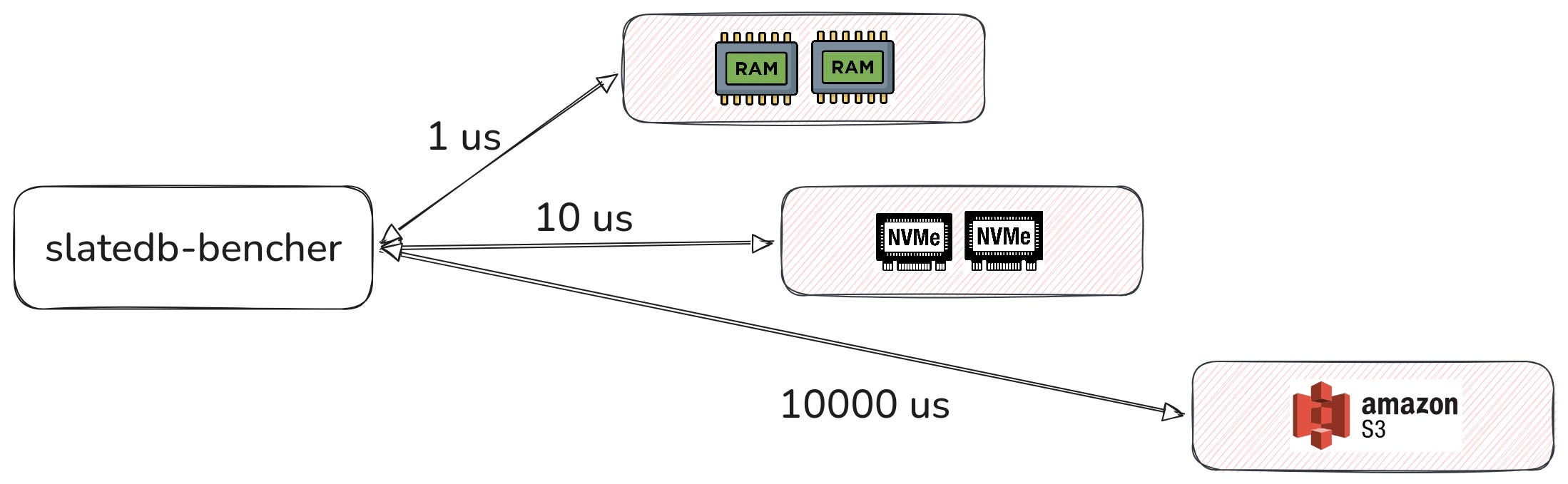
Instead of reinventing the wheel, I used the official slatedb-bencher tool and added RocksDB support to it.
RocksDB obviously doesn’t support S3-based persistence out of the box. An abandoned fork of RocksDB-Cloud exists, but I’m leaving that out of scope for this test. But for this benchmark, I wanted to test the “all data is hot and already cached on local disk” scenario.
The reasoning is pretty simple:
Pure cold-data benchmarks would mostly measure S3 latency, which is usually 10ms+ and would dominate everything else.
Many ML inference workloads also have a Pareto-style access pattern: a small slice of the data gets hit most of the time. Something like 10% of the data serving 90% of the reads is pretty common.
I kept the workload from slatedb-bencher as-is:
mixed workload: 80% reads, 20% writes, with no warmup;
100M keys, 16-byte keys, 256-byte values;
concurrency levels of 1, 2, 4, and 8 workers;
95% of reads use warm keys, while 5% are random.
I also tried to keep the RocksDB and SlateDB settings reasonably comparable:
both engines get the same 4 GiB block cache, so memory usage should be in the same ballpark;
SlateDB runs against a local object store backend (CLOUD_PROVIDER=local), flush_interval=100ms, wal_enabled=true, await_durable=false;
with that SlateDB setup, writes return as soon as they hit the in-memory buffer, so durability is bounded by the 100ms flush timer;
RocksDB runs with the same 4 GiB LRU block cache, 10 bits/key bloom filters;
Everything else is RocksDB defaults: WAL on, no explicit fsync, auto compaction.
All tests were run on a 16-core x86_64 Linux machine with 64 GiB RAM, a Ryzen 7 7700X CPU, and a 2 TB M.2 NVMe drive.
Results
The first round of benchmarks tested different concurrency levels.
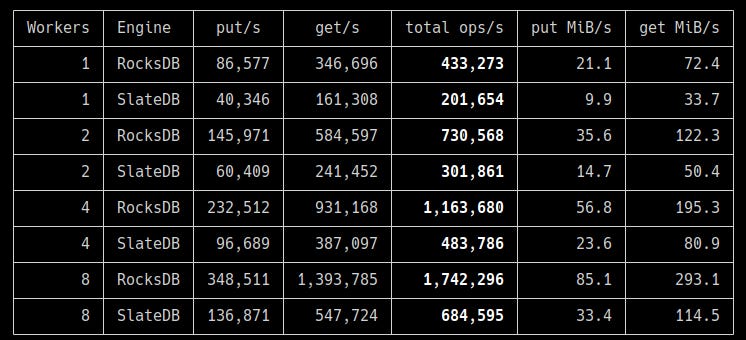
As you can see, RocksDB is more than 2x faster in raw read/write throughput.
But from a system utilization perspective, SlateDB looks surprisingly good:
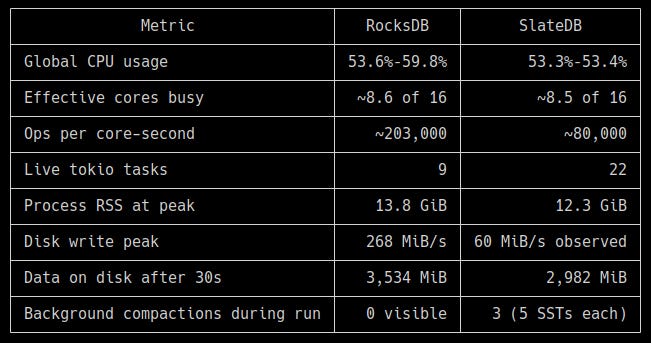
Memory usage is roughly similar between the two engines, but SlateDB shows much lower write amplification, even after adjusting for the smaller number of operations completed.
Conclusion
SlateDB is not a drop-in “RocksDB, but on S3” performance replacement - at least not yet, and definitely not in a fully local hot-data benchmark. But the numbers we got here are still encouraging.
For MurrDB, this is good enough to keep SlateDB on the table. Since MurrDB supports pluggable storage backends, I’ll probably implement SlateDB as an additional backend and keep RocksDB around as the baseline.