
How [not] to evaluate your RAG
A true journey of building a RAG system for a fintech company. The first version technically worked, but was terrible. We tore it apart and evaluated each piece to make it less terrible each time.


This is a text version of a conference talk “How [not] to evaluate your RAG“ by Roman Grebennikov on Berlin Buzzwords 2025: see [slides] and [youtube] if you cannot into long-reads.
How it all started
The good thing about reinventing the wheel is that you can get a round one. [source]
Some people unwind in the evenings by playing video games. I'm no different, except my game of choice is called “build a modern S3-based search engine (almost) from scratch.”, see https://github.com/nixiesearch/nixiesearch if you’re curious.
I say “almost” because I’ve taken a shortcut: instead of reimplementing everything in [blazingly fast] Rust, I went with Apache Lucene: the same battle-tested search library that powers Elasticsearch, OpenSearch, and Solr.
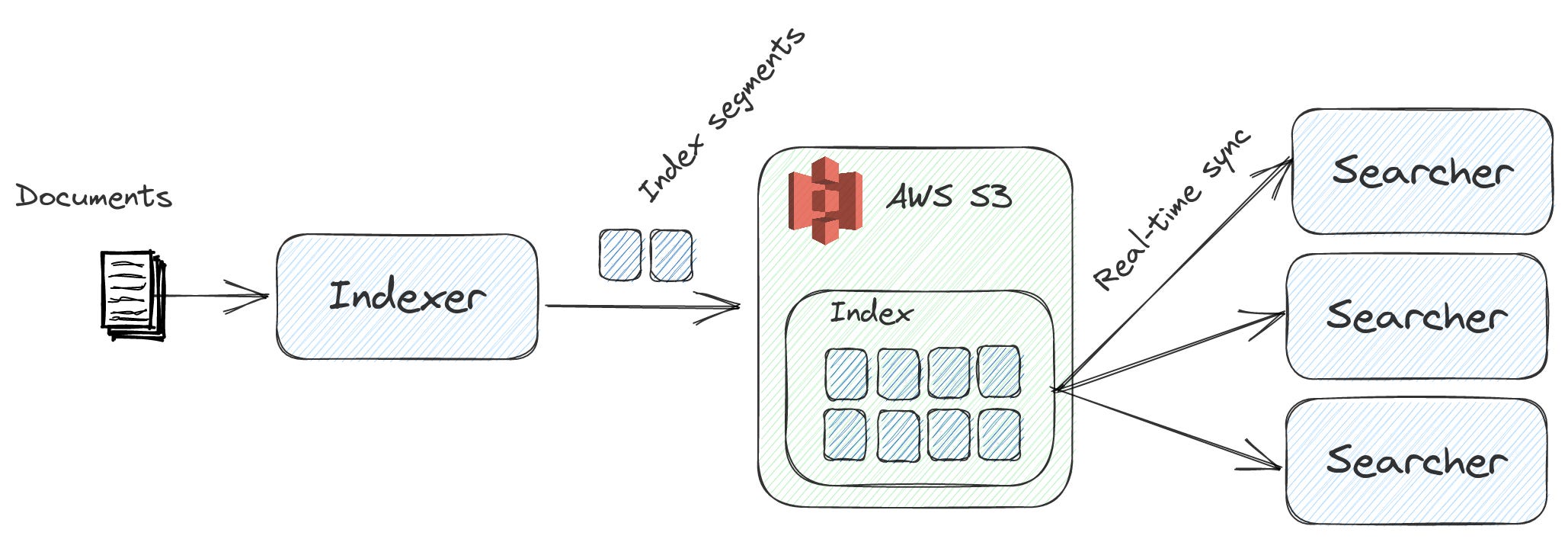
Lucene handles all the algorithmic heavy-lifting, so I get to focus on building nice developer-friendly features of Nixiesearch:
S3 block storage support for index replication (and direct cold search)
All the classic Lucene things: facets, filters, autocomplete, lexical and vector/semantic search
Modern (but already commoditized) “AI/ML search” stack: embedding inference, reranking and RAG.
You build it, they run it
Nixiesearch is open-source, with no VC or corporate backing, so we fully embrace the no-gatekeeping approach. But that also means you occasionally get some surprising conversations in the community Slack after dropping a big feature, like local RAG support:

Naturally, we couldn’t resist the curiosity. We jumped in to see what kind of issues someone might have with a freshly released feature (I mean, what could possibly go wrong?).
Support agent for support agents
The idea behind this project was to build a non-human assistant for human customer support agents. Anytime you launch a B2C app, regular folks are bound to run into issues and start messaging your team with pretty standard stuff.
If you’ve ever worked in customer support (I have, once), you know the drill: you could handle 80% of tickets in your sleep.
The end goal was to free up time for the remaining 20% of truly hard tickets, and to make onboarding new team members way easier. The end result should look something like this:
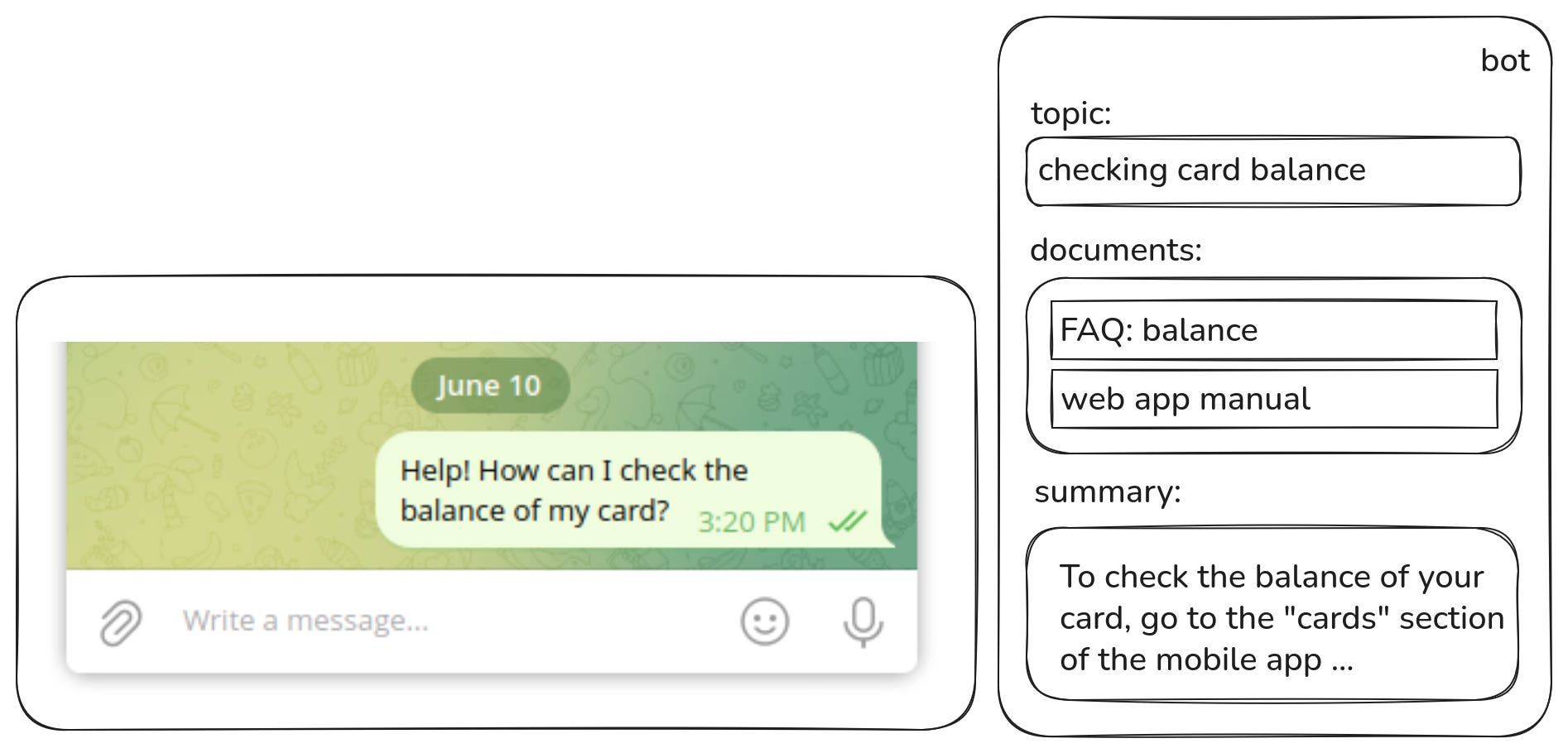
There’s always a human in the loop (because let’s face it, nobody likes getting GPT-generated replies instead of real support). The agent can either approve the suggested answer or jump in and write their own.
It’s basically a textbook RAG setup with one small twist: you first need to extract the actual request from the conversation. After that, it’s business as usual:
Retrieve all relevant documents from the knowledge base,
Pack them into the prompt of the LLM,
Generate a one-sentence summary as an answer for the original request.
Getting real
There's usually a big gap between textbook RAG setups and real-world deployments, thanks to all those unexpected limitations nobody thinks about at first.
As it’s a fintech company, you simply can't dump customer financial details into the OpenAI API - regulations aside, it's probably just a bad idea. Can it be totally air-gapped?
The company was operating in the CIS region, so the app primarily needed to speak Uzbek and Kazakh with occasional bits of Russian and English. How confident are you that your local LLM can handle these low-resource languages?
Knowledge base often scattered in surprising places: Slack threads, notes scribbled on napkins, post-it stickers on the office fridge.

According to LinkedIn and Twitter/X experts, LLMs are magical: they effortlessly solve just about any problem. So naturally, we decided to vibecode build a textbook RAG setup directly on top of Nixiesearch, so no changes needed:
Convert all documents we found straight to Markdown,
Chunk sentences using LangChain,
Embed everything with intfloat/multilingual-e5-small,
Summarize with Qwen2.5 (since Qwen3 wasn’t around yet).
Here is me casually vibecoding similar RAG setup in about 60 seconds with Claude Code:
Sure, we might’ve done a little better than Claude. But the whole point was to quickly hack together a first prototype, put it in front of actual users, and start gathering feedback. Because, let’s face it, you probably got almost everything wrong anyway.

And indeed, after evaluating our fancy CTO@K metric (rather than classic search metrics like NDCG@K), the feedback came back just as rough as expected:
“Technically, it works—the dialogues get summarized, documents show up, and answers get generated—but honestly, it all kind of sucks.”
Documents retrieved were often irrelevant, while many relevant ones never surfaced - so these are retrieval failures. Requests and answers frequently turned out either factually incorrect or linguistically off - these are generative failures.
You could just start throwing different things at the wall and running more CTO@K tests until something sticks (or the CTO gives up), but in reality, you don’t get that many chances.
RAG evaluation frameworks
There’s no shortage of RAG evaluation frameworks out there: RAGAS, DeepEval, LangSmith, LangFuse, LangWhatever. But most of them take a similar approach: since RAG is really a pipeline of document preprocessing, retrieval, and generation, they break it down and evaluate each piece separately:
How you chunk the documents,
Classic search relevance metrics,
Generation quality,
End-to-end performance.
So, naturally, we started with chunking.
Chunking
To build an answer, the underlying LLM needs the most relevant context for the request. But context is expensive: sure, modern LLMs boast impressive context lengths (128k+ tokens), but feeding such huge contexts into the model means higher costs and longer waits.
Since most evaluation frameworks didn't offer chunking-specific metrics, we ended up doing a good old vibe-based evaluation: use your own system, watch where it breaks, and fix the most obvious issues first.
Given the relatively small dataset we had, we considered using large chunks, or even no chunking at all. In practice, that meant when you searched for a query, you might end up getting an entire document back as the search result:

There are two main issues with this approach:
Vector search is like lossy compression. The larger the document, the more it gets "compressed" into a single fixed-size embedding—meaning fine details are often lost along the way.
There's still a human in the loop. As a support agent, skimming through five short, relevant snippets is doable. But nobody's going to read through five 200-page documents while a customer is waiting on a reply right now (and not in an hour).
Okay, but if you go too far in the other direction and make your chunks too small… now you’ve got a different problem: lost context.
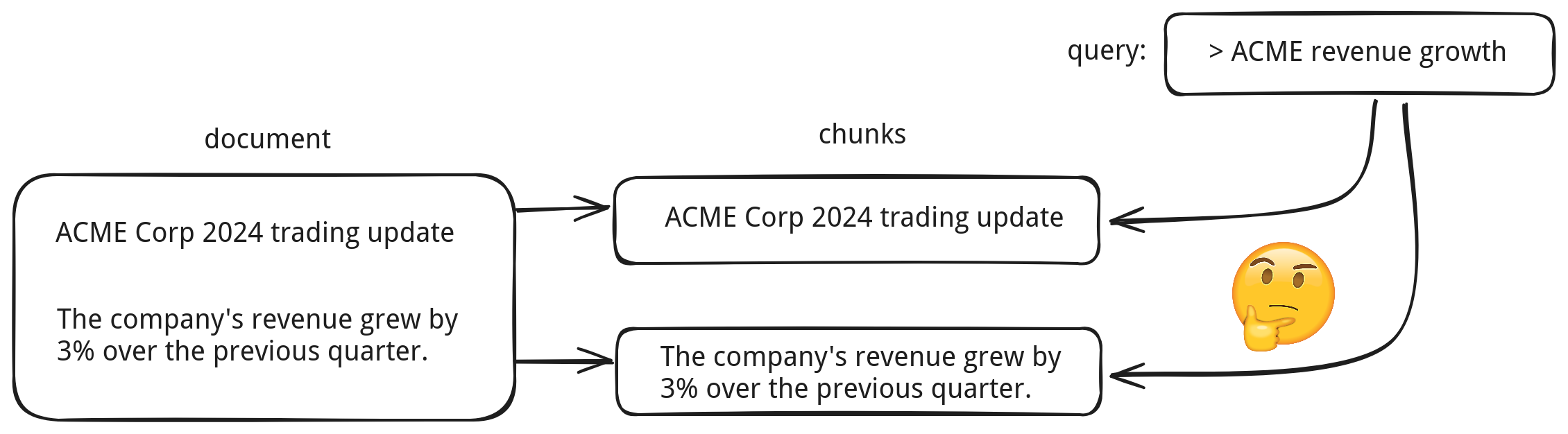
When we split documents into chunks that were too small, we started losing important cross-references. Facts that were clearly connected in the original text became ambiguous. Like: "Which company’s revenue grew by 3%?"—the answer was probably just a few lines up, but now it’s gone.
In 2024, Anthropic proposed an alternative called Contextual Chunking:
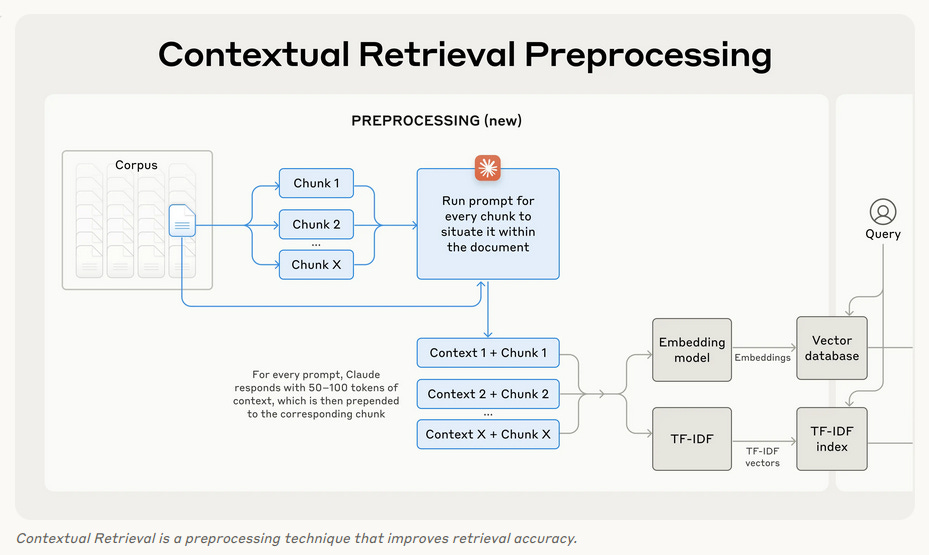
For each chunk, you prepend some document-specific context. Sounds great in theory, but running LLM inference on every chunk can get expensive and slow.
Fortunately, we weren’t building a general-purpose system for all document types. Our corpus was fairly specific, and followed a flat Markdown structure. So we asked ourselves: what if we just use the paragraph title as context?
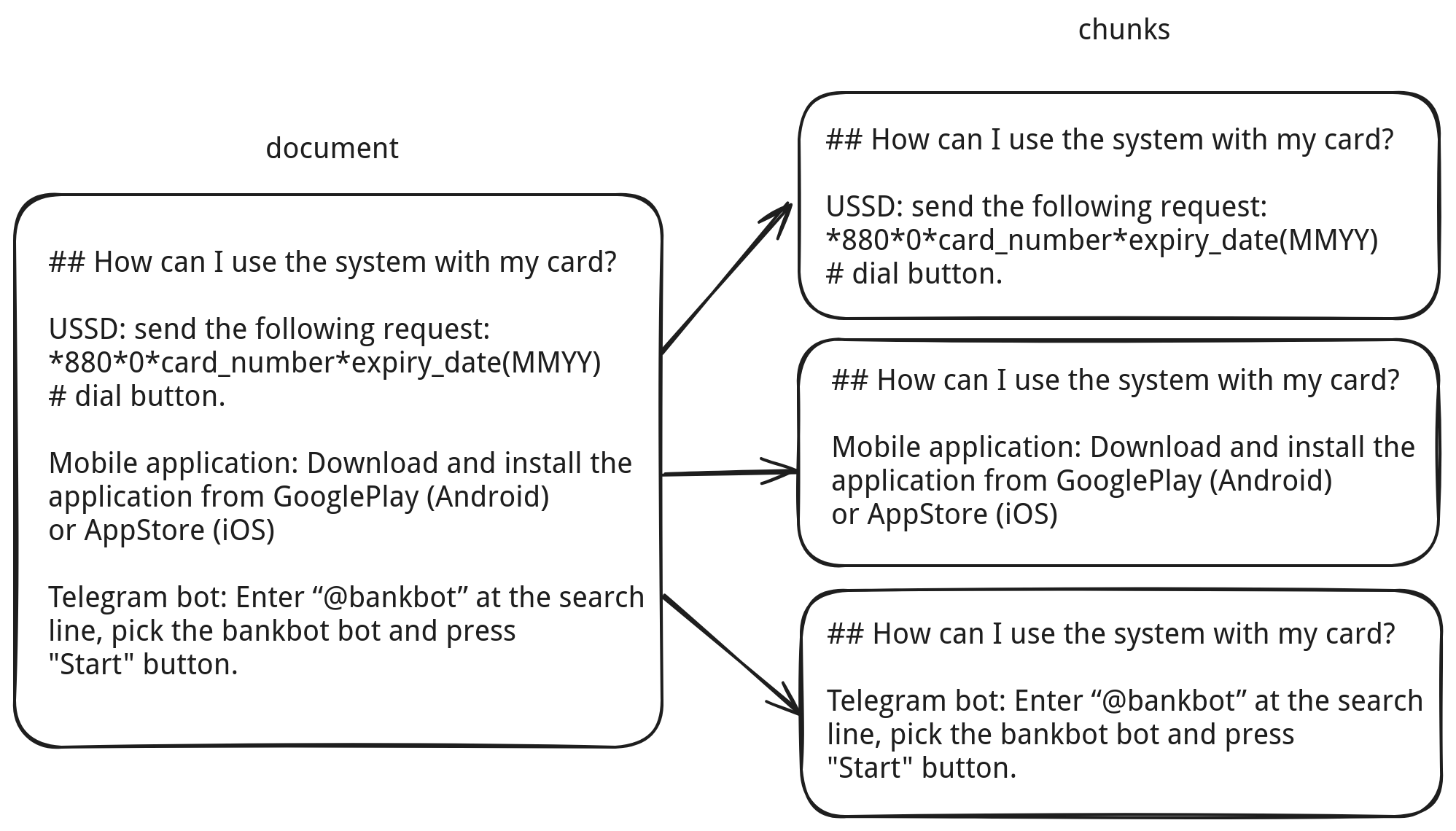
Sure, it depends on your data. In something like Wikipedia, titles are often just 1–2 words and not very helpful. But in our case, titles turned out to be great context carriers. We called this approach "GPU-poor contextual chunking."
Surprisingly, it worked. It fixed most of our lost-context issues. Is it super scientific? Not really. But it did the job, and that’s what mattered.
Document ingestion pipeline
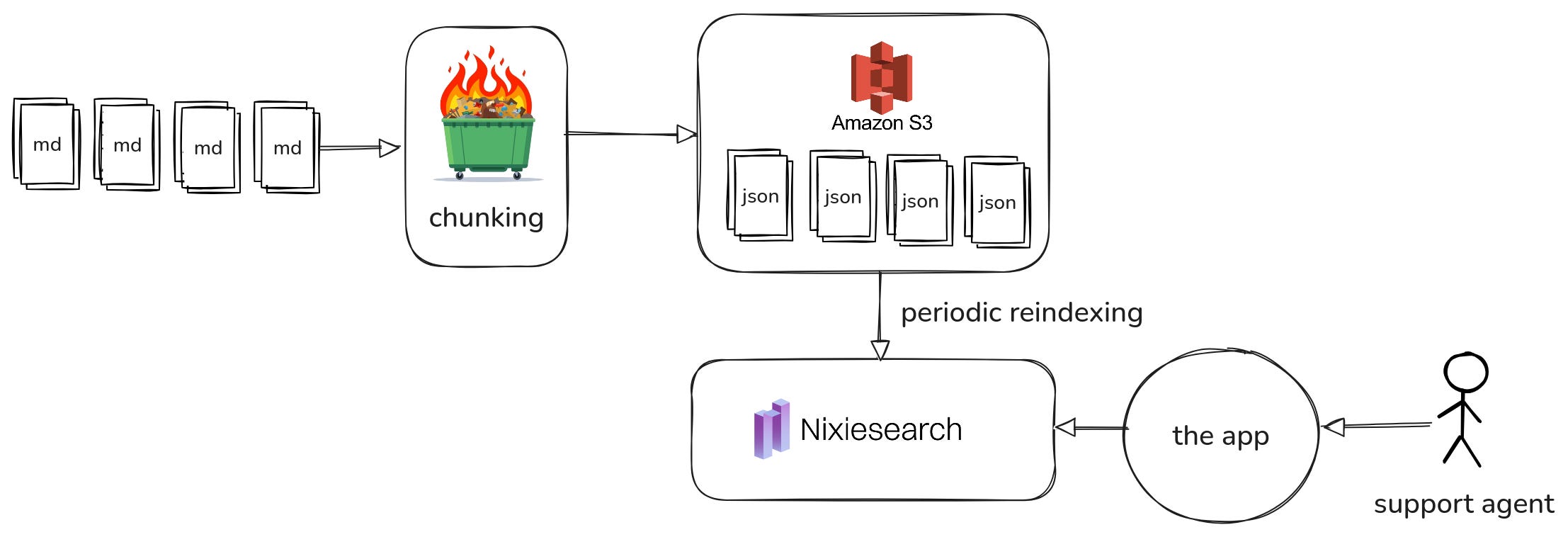
There are plenty of chunking frameworks out there (Chonkie even has a SaaS version!), but given how simple our chunking logic was, we chose not to overcomplicate things.

All our Markdown documents were processed in a single batch job, which output a set of chunked documents to S3-compatible block storage. On top of that, we run a periodic offline incremental reindexing job for Nixiesearch that writes a new index version to S3.
$> nixiesearch index file -c config.yml --url s3://bucket --index hello
$> aws s3 ls s3://bucket/hello
-rw-r--r-- 1 shutty shutty 512 May 22 12:55 _0.cfe
-rw-r--r-- 1 shutty shutty 123547444 May 22 12:55 _0.cfs
-rw-r--r-- 1 shutty shutty 322 May 22 12:55 _0.si
-rw-r--r-- 1 shutty shutty 1610 May 22 12:55 index.json
-rw-r--r-- 1 shutty shutty 160 May 22 12:55 segments_1
-rw-r--r-- 1 shutty shutty 0 May 22 12:48 write.lock
$> nixiesearch search -c config.ymlThe searcher backend just picks up the latest index, and that’s it.
The R in RAG
When you (as a search engineer) first open a list of RAGAS supported evaluation metrics and see things like Precision, Recall and Relevance, you might think that you’ve seen these names already somewhere else.

The goal of retrieval is to give the LLM the most relevant context. Otherwise, it’s just a classic garbage in, garbage out situation. But with our unusual target languages, the big question was: which search implementation should we trust?
For lexical search, we quickly ran into a roadblock: there are no well-tested, Lucene-compatible analyzers for Kazakh or Uzbek.
On the vector side, some XLM-Roberta-based embedding models (like the Multilingual-E5 family) claim to support these languages. But how do we actually validate that?
There aren’t any labeled datasets available in Kazakh or Uzbek. So we thought—what if we just machine-translate an existing dataset like MIRACL? This idea isn’t new: the mMARCO paper showed that using machine-translated training data can significantly improve multilingual retrieval quality.
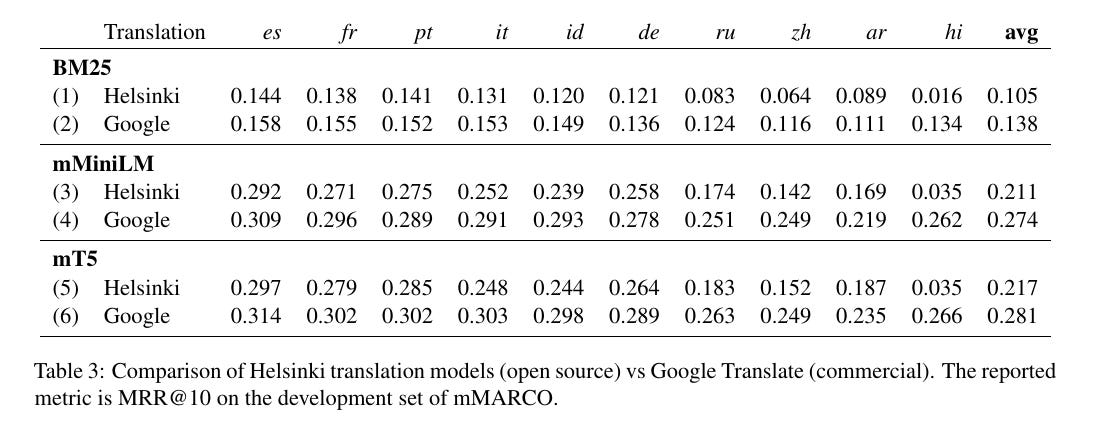
The mMARCO paper used the Helsinki Opus MT model from 2021—but by today’s standards, Google Translate easily outperforms it. That got us thinking: could we use modern LLMs as translation engines?
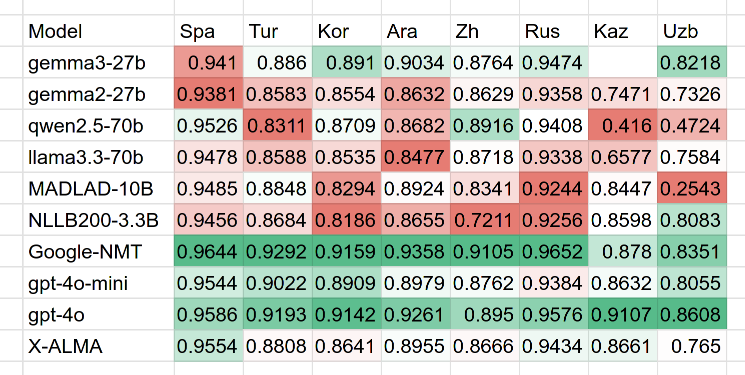
To test that, we ran a quick evaluation on the FLORES-plus dataset using the XCOMET metric across various language pairs (en→xx). The results? For low-resource languages like Kazakh and Uzbek, GPT-4o outperformed Google Translate both in translation quality and cost.
So, we took the English split of the MIRACL dataset, translated it into Kazakh and Uzbek, and ran the MTEB benchmark across all the open-source multilingual embedding models we could get our hands on.

We originally expected multilingual-e5-large to be the top pick—but surprisingly, the much larger BAAI/bge-multilingual-gemma2 model performed significantly better for our target languages.
For context: this experiment was done before Qwen3-Embedding came out. It’s now one of the strongest multilingual embedding models available
LLM embeddings and ONNX
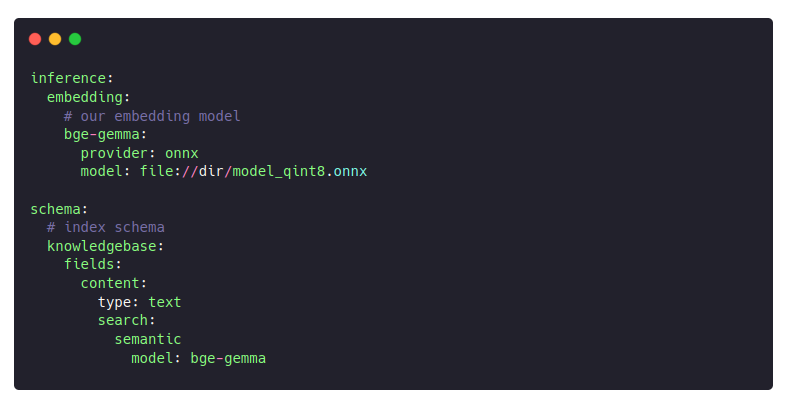
Gemma2 isn’t your typical encoder-based embedding model like everyone’s used to. Nixiesearch uses ONNX as the runtime for embedding inference, so we were a bit cautious going in. But to our surprise, the ONNX export worked flawlessly with the latest version of sentence-transformers.

Even better: we didn’t have to touch a single line of our model loading code. Hard to believe, but… it just worked:
Retrieval metrics
Once the retrieval stack is in place, it’s time to measure how well it’s actually working. Traditional search evaluation relies on human-labeled relevance data—“Is this document relevant to this query?”—to compute metrics. But frameworks like RAGAS offer a faster and cheaper alternative using synthetic labels.
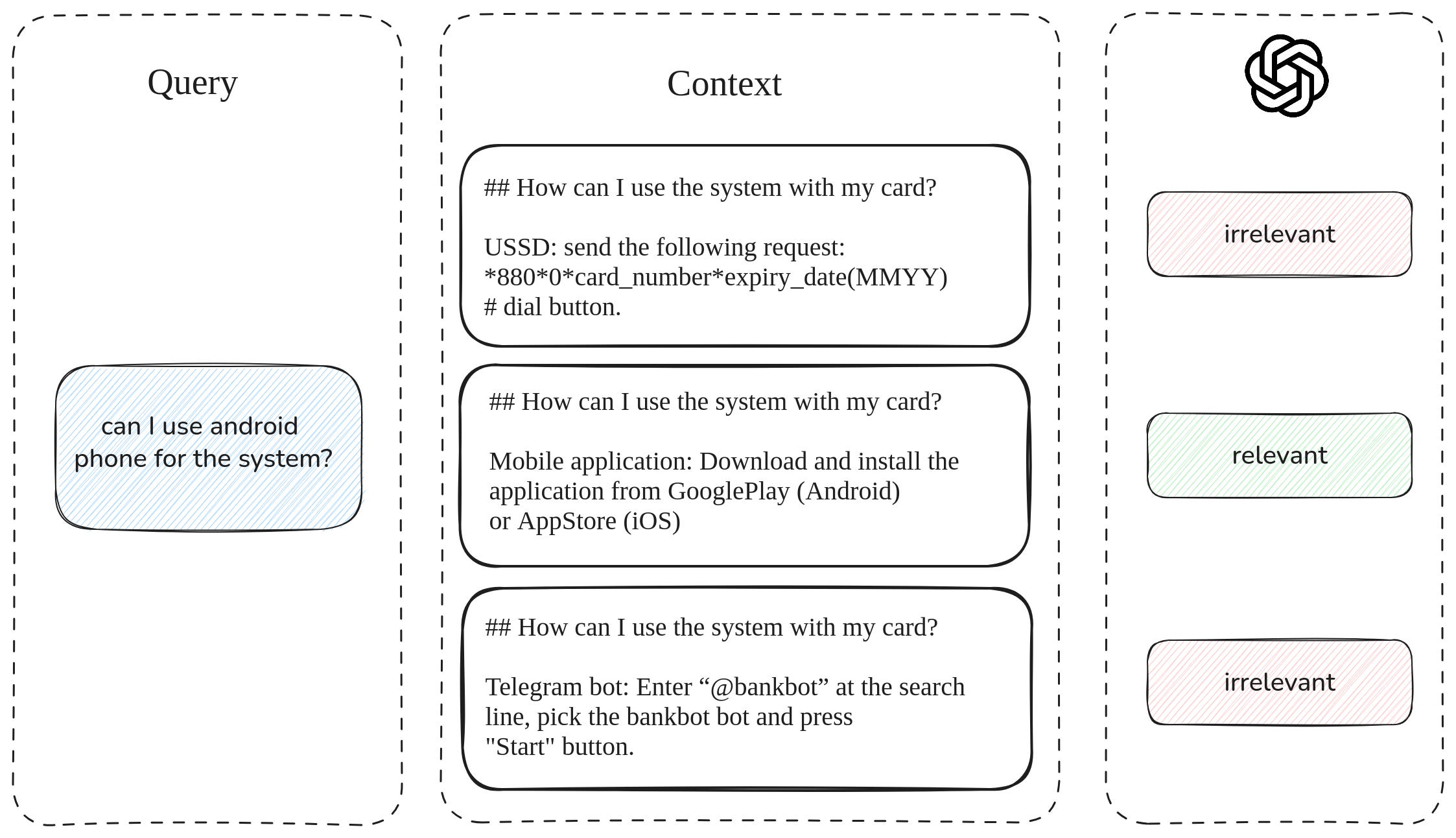
One popular method is the LLM-as-a-judge approach: you ask an LLM the same question you'd pose to human annotators and use its response to compute metrics like context precision and recall. But since the context is usually a fixed size (e.g., top-10 documents), you can also skip generation and just look at query-document similarity scores from your embedding-based retrieval.
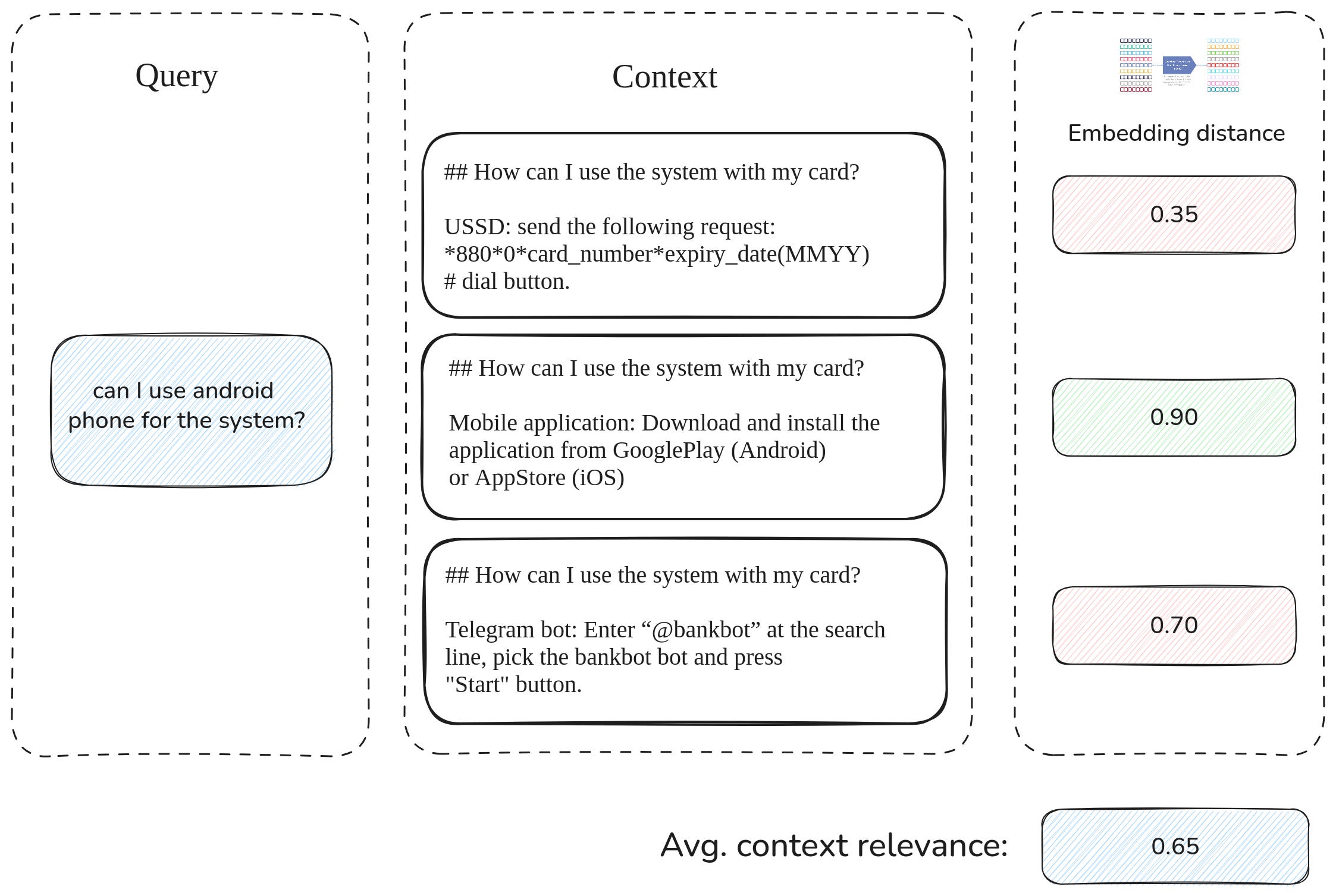
Sure, these metrics might not be super meaningful as absolute numbers, but if your iteration loop is fast (say, under a minute), you can watch them improve over time.
The G in RAG
The generative part of RAG rests on two key pillars:
Comprehension – the LLM needs to understand both the task and the context
Generation – it has to produce a grammatically correct and coherent response
To evaluate comprehension, we found Belebele, a multilingual NLU dataset from Facebook that includes splits for our target languages. A typical task looks like this:
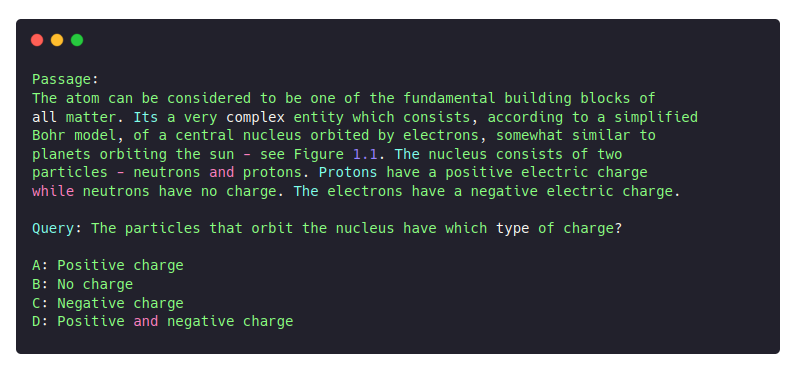
We tested two different prompting strategies:
English Instructions (Cross-lingual): task instructions in English, with content in the target language
Translated Instructions (Monolingual): both instructions and content in the same target language
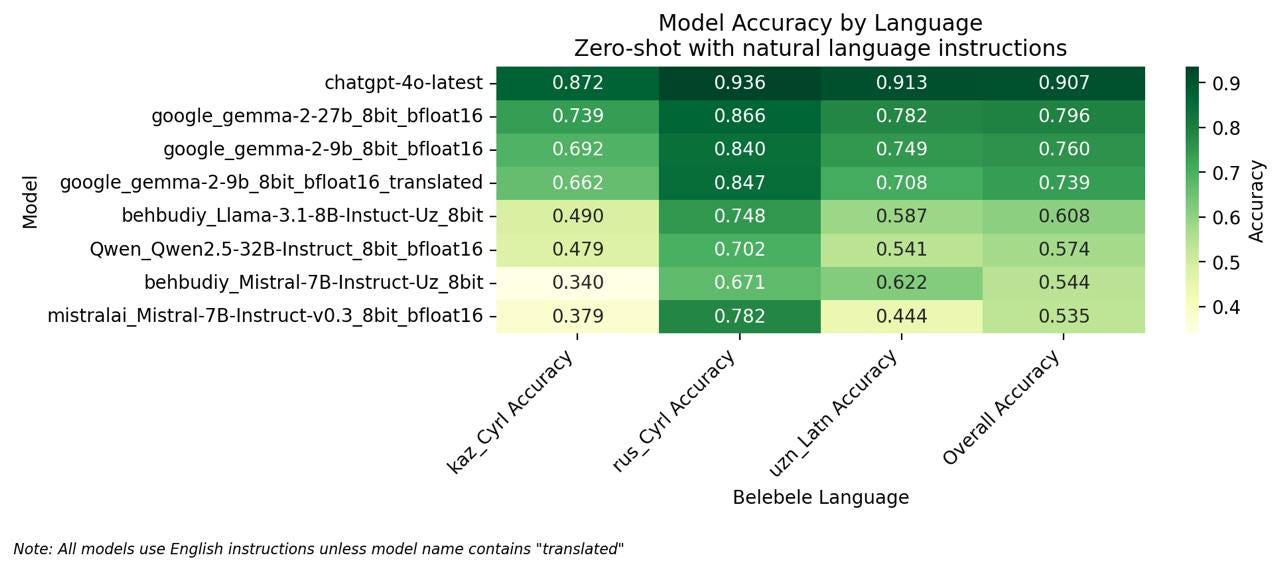
As expected, GPT-4 still leads, but Gemma2 came surprisingly close. The biggest learning? Using English prompts for non-English tasks actually gave us better comprehension performance.
Side note: At the time of this experiment, Gemma3 hadn’t been released yet.
Measuring the smoothness of generated text is inherently subjective, so we chose a more objective proxy: perplexity. It gives us a sense of how naturally a model can generate text.
Perplexity measures how "surprised" a language model is by a given piece of text. When a model reads text, it constantly predicts the probability of each upcoming word. Perplexity is calculated as the exponential of the average negative log probability across all tokens.

Intuitively, perplexity represents "on average, how many equally likely choices did the model think it had at each step?" A perplexity of 10 means the model was as uncertain as choosing between 10 equally likely options, while a perplexity of 2 suggests much higher confidence.
We evaluated corpus-level perplexity across five corpora:
Client data: Manual Russian and Uzbek knowledge base texts
Benchmark data: 100 sampled passages each from Russian, Kazakh, and Uzbek Belebele splits.
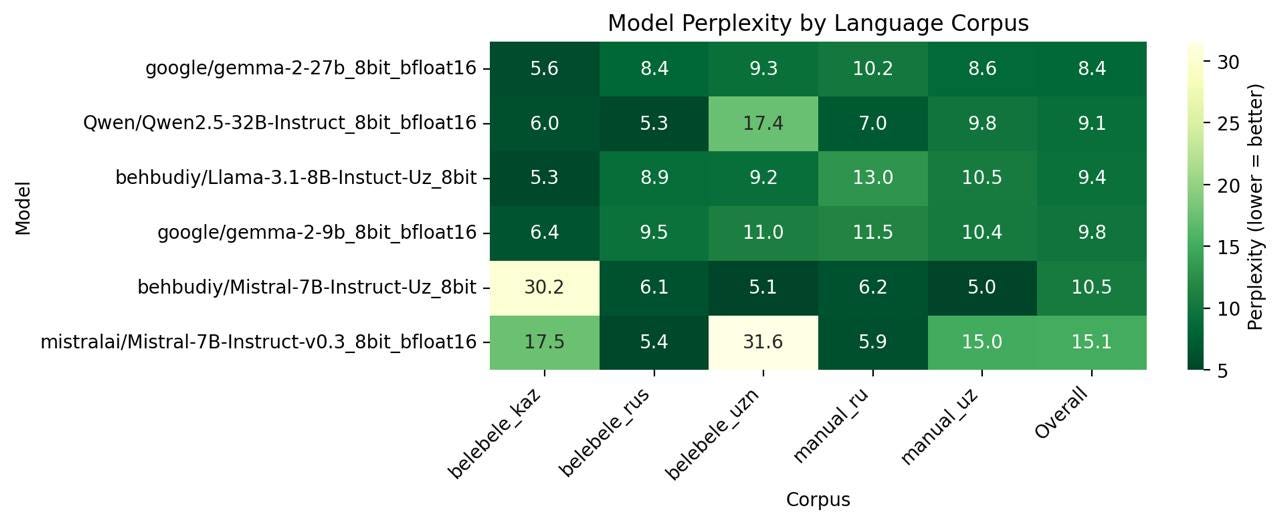
Gemma-2-27B somehow just works across everything we threw at it: both comprehension (79.6%) and generation quality consistently delivered.
Things we haven’t tried
RAGAS and similar frameworks have a couple of useful metrics for the end-to-end evaluation:
Answer accuracy: compare prediction and ground truth. Of course, if you have ground truth.
Answer groundness: is answer based on context?
Under the hood these metrics are all LLM-as-a-judge based, just wrapping prompts and response parsing code.

You’re not really limited to only these two end-to-end metrics, and can make your own, if you follow a couple of best practices:
bad example:
is document '{doc}' relevant to query '{query}'?good example:
classify '{doc}' relevance to query '{query}':
score 0: doc has different topic and don't answer the
question asked in the query.
score 1: doc has the same or similar topic, but don't
answer the the query.
score 2: document exactly answers the question in queryGetting all together
Implementation-wise, we made a single-node deployment with all embedding and LLM inference happening locally.
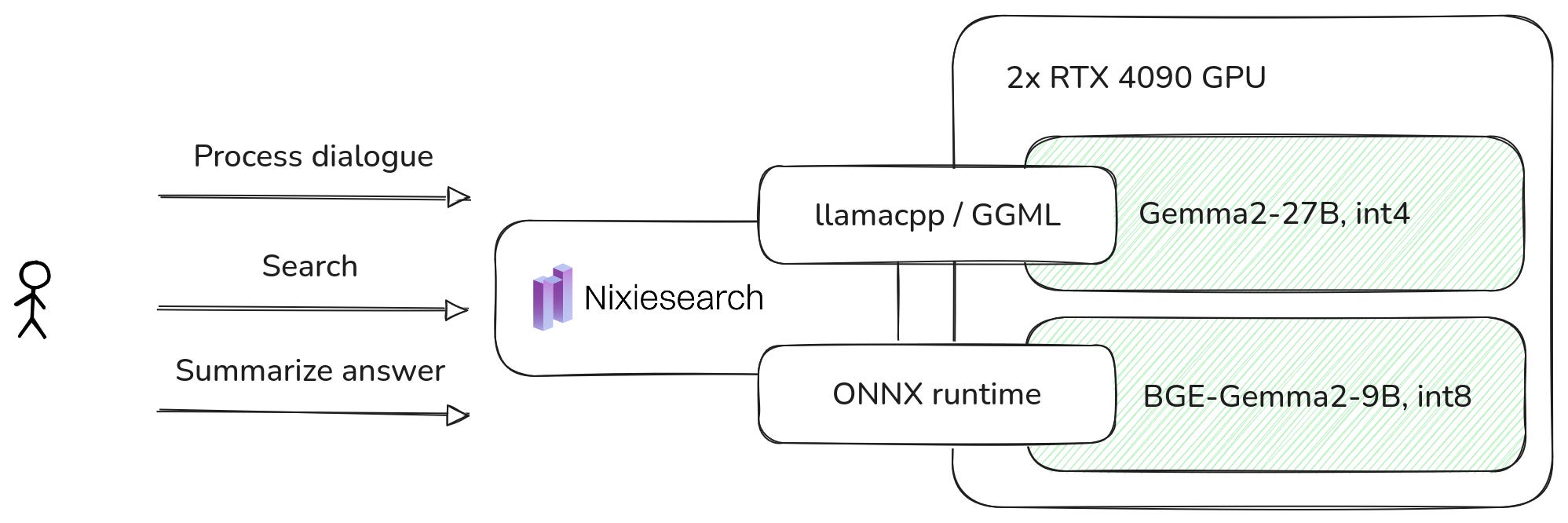
The whole system runs on-prem on a single 4U server with 2x RTX4090 GPU, but with free room for more.
We managed to get 500ms latency to first token, and 100 tps generation speed.
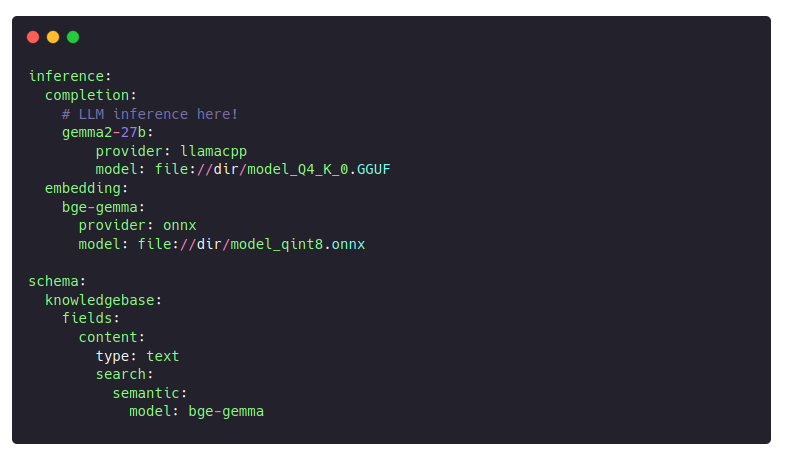
A complete Nixiesearch config was pretty basic, with just a single text field for the chunk context:
Things we learned
English >> High-resource >> Low-resource languages
Language support quality still follows the classic hierarchy. English models are the most robust, high-resource languages perform decently, and low-resource languages often require creative workarounds.Decompose early: complex system = many simple parts
A full RAG pipeline might look intimidating, but once you break it down to chunking, retrieval, generation, evaluation, it’s just a series of manageable components. Treat each one like a standalone problem.LLM-as-a-judge: when you have no choice
When you lack labeled data or time, synthetic evaluation using an LLM is a practical (if imperfect) solution. It’s not scientific perfection, but it moves the needle.
At the end of the day, building a good RAG system is less about magic: and more about debugging, duct tape, and iteration.
 | A guest post by
|