
Nixiesearch: running Lucene over S3, and why we’re building a new serverless search engine
A new search engine in 2024? Yes, but stateless — index on S3, serverless — no cluster state, with all Lucene features — filters, autocomplete, facets. And also with local embedding & RAG inference.

Nixiesearch: running Lucene over S3, and why we’re building a new serverless search engine
This is a long-read version of a Haystack EU24 conference talk by Roman Grebennikov. Check out the slides or watch the video if you’re a Gen Z.
If you’re running a large search engine deployment, you already have a personal list of things that can go wrong on a daily basis.
In this post we are going to:
Complain about existing search engines ops complexity. I’m looking at you, Elasticsearch and SOLR.
Hypothesize about running Lucene-powered search in a stateless mode over S3 block store. Why do you even need a stateless search over a block store?
Introduce Nixiesearch, a new stateless search engine, and how we struggled to make it work nicely with S3. And how it ended with RAG, ML inference and hybrid search.

Unlike regular back-end applications, search engines nowadays are considered special and require additional “like a database” handling. The prize wheel above summarises author’s personal incident experience with Elasticsearch, OpenSearch and SOLR — but other modern vector search engines such as Weaviate and Qdrant are not immune.

Each of your search nodes is stateful and contains a tiny part of a distributed shared mutable index. And if you’ve ever read at least one book on systems design and engineering (such as the “Designing Data Intensive Applications” by M. Kleppmann), you’ll perfectly know that things aren’t going to be smooth sailing when there’s a “distributed shared mutable” in the name:
Each node depends on an attached storage — which makes cloud deployments much more fragile with EBS disks, PersistentVolume and PersistentVolumeClaims over DaemonSets.
To perform auto-scaling you need to redistribute state across nodes. Since scaling is usually triggered when the cluster is already under load, and the redistribution process also adds additional load — we usually just over-provision instead.
Worse still, this internal state also spawns outside of the search engine itself, as the entire indexing pipeline is also tied to it.

Stateless search?
The idea of stateless search engines is not new, as they already exist in the wild:
Yelp NRTSearch, built on top of Lucene near-real-time segment replication. Works over gRPC and supports only lexical search.
OpenSearch when configured for segment replication over remote-backed storage. With this mode of operation, index is stored externally, but the cluster state is not.
Quickwit for log search over S3 storage. A great alternative to the ELK stack, but not for consumer-facing search.
Turbopuffer doing HNSW-like vector search over S3-based block storage. SaaS only, but written in Rust.

The main point of these search engines is to decouple computation (e.g. the actual search process) from the storage. There are also examples in the industry of large companies migrating to stateless search:
With all these great in-house search engines being not available for general audience, what should we do?

Introducing Nixiesearch
Nixiesearch is a Lucene-based search stateless search engine, inspired by the Uber, Doordash and Amazon designs from the articles above:
Started as a proof-of-concept that Lucene could be run over the S3-compatible block storage.
Went further with many modern features implemented on top: hybrid search, RAG and ML inference.
There have been a number of experiments back in the days to add S3 support to Lucene, starting from 15 years ago by Shay Banon (a creator of Elasticsearch, and now a CEO of Elastic):

Lucene over S3
Lucene is has an IO abstraction called Directory — a high-level API to support almost any data access method:
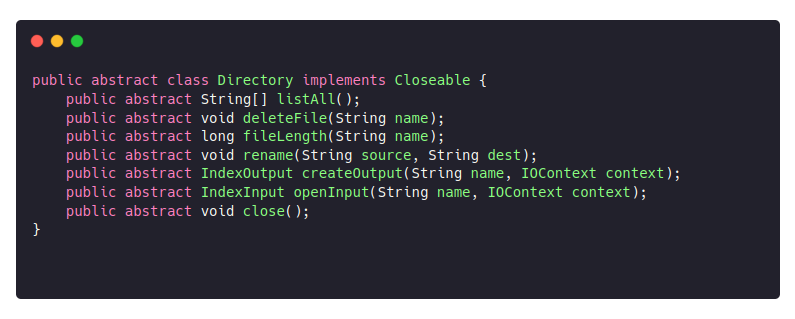
There are many Directory implementations available ranging from practical ones like MMapDirectory and ByteBuffersDirectory, to the much more experimental and obscure JDBCDirectory. And the Directory API maps quite nicely to the S3 API operations, so it’s no surprise that there’s already one brave soul who’s made the S3Directory:
Lucene itself is a synchronous library built on the main assumption that your index data is stored locally, but this is no longer the case with S3Directory.

The S3Directory itself is implemented by naively mapping Directory calls directly to the S3 API without any intermediate caching, and its README mentions that performance is not great:

With 100x higher data access latency, it’s not a surprise to see 100x slower end-to-end times.
An obvious improvement to this approach is to introduce the read-through caching support — that’s what we did in the first version of Nixiesearch.
Read-through caching for S3Directory
The main assumption behind the caching idea is that the Lucene index may have hot spots, and there is no reason to make an S3 API call for index blocks we have already read in the past:
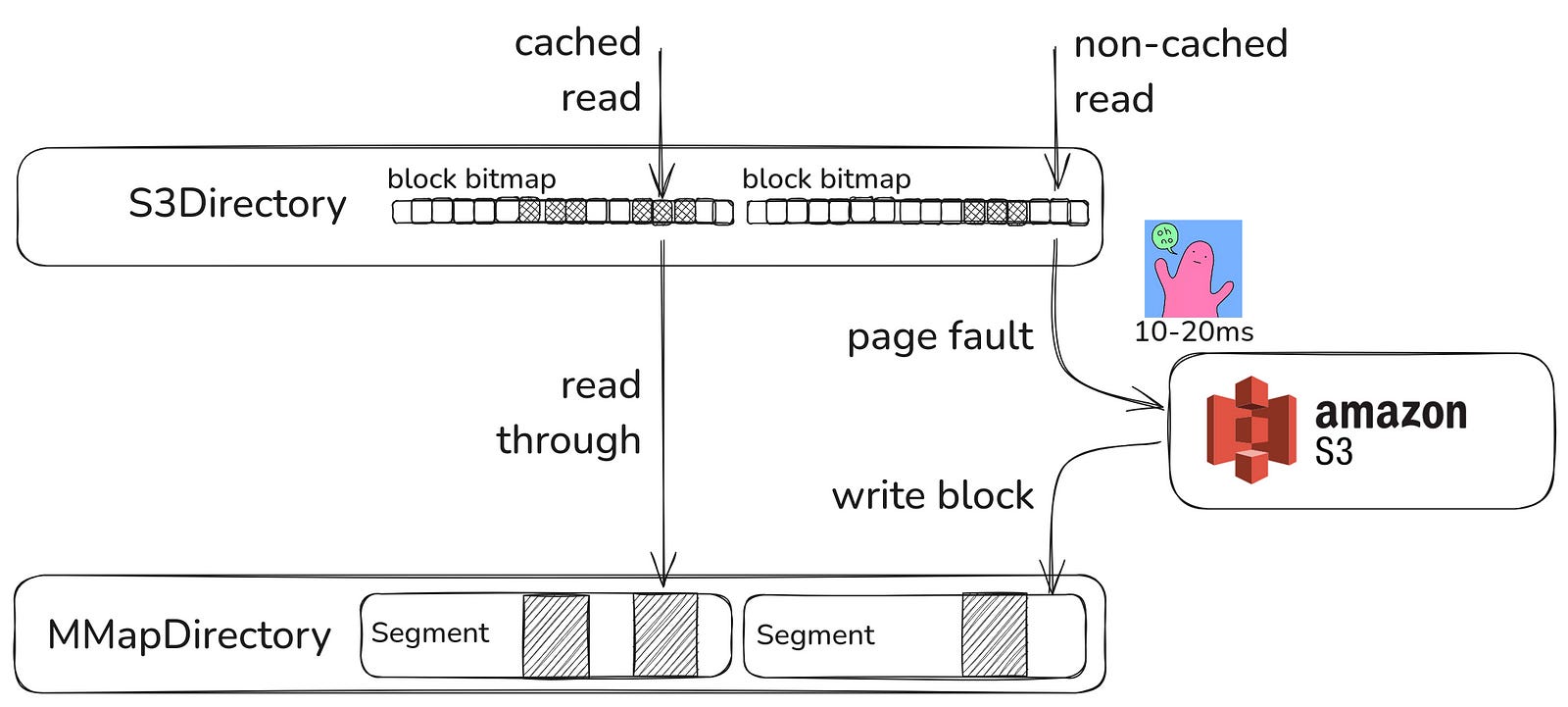
With this approach, the S3Directory is implemented just as an ephemeral caching layer on top of the regular MMapDirectory, with the main benefit of making the whole search application stateless! But what’s the latency cost?
How slow is S3 in practice?
AWS S3 latency
Today, S3 has become a protocol, and not just an AWS service, but being implemented by GCP, Minio and many otherproviders. The AWS S3 reference implementation has two API flavors:
Traditional S3: geographically redundant, with higher latency.
S3 Express: limited to a single AZ, but with much lower latency.
We implemented a small nixiesearch/s3bench tool to measure a first byte latency for S3 GetObject API request across different endpoints:

The main observation we made is that the first byte latency of S3 Express is actually only 5ms instead of 20ms for a traditional S3. And this latency is independent of block size.

For the last byte latency both curves for S3 and S3Express are almost parallel, so we can assume that the only difference between these two implementations is in much lower constant value of initial request latency, due to S3Express using pre-signed access tokens — so there is no need to perform a full IAM role evaluation on each request.
Searching in MSMARCO on S3Directory
Synthetic micro-benchmark latencies are nice, but what are the real-life numbers we get when searching through a read-through block cache for S3Directory? Let’s do an experiment:
Take a well-known dataset like MSMARCO, with sample sizes of 10k, 100k and 1M documents.
Implement a traditional HNSW “vector search” index on top of S3-backed Lucene. We will use a Microsoft e5-base-v2 embedding model with 768 dimensions, and a single-segment index.
We will use the default Lucene HNSW index settings of M=16 (so the number of neighbors for each node in the graph — this number is going to hit us hard later) and efConstruction=100.

There are a lot of numbers in the table above, but here are two most surprising facts:
For a small 10k docs dataset, the first request fetched almost 30% of the entire index while traversing the HNSW graph.
For a larger 1M docs index, we performed over 300 read operations to S3, resulting in a whopping 3 seconds of latency.
What is going on here, why do we need so many reads to perform a simple nearest neighbors search?

Because Lucene uses an HNSW algorightm to perform a nearest neighbors search, it needs to traverse a large multi-layer graph:
Each layer of the HNSW graph contains links to neighbor nodes. Top layers have only long links, and bottom layers have only short links.
At each step of the graph traversal, we pick a node and evaluate a distance between a query and a neighbor — so we need to load this neighbor embedding from the storage.
Each such evaluation is effectively a random cold read from S3, adding yet another +10ms to the request processing latency.
You may be wondering, “OK, but this is a first cold request, will it get better over time?”

Unfortunately we found out that the read distribution over the HNSW index still stays quite random, and the initial hypothesis that there are index hotspots is not true:
e2e latency goes down from 3 sec to 1 sec on request #32. Things are getting better, but 1 second search latency is still not acceptable for a consumer-facing search.
On request #32 we are already reading 30% of the entire index.
So the idea of doing HNSW search over S3-backed block storage is nice in theory, but not very practical in reality, isn’t it?

Lucene 10 I/O Concurrency
But it’s not all doom and gloom: the upcoming release of Lucene 10 includes the ongoing initiative “Improve Lucene’s I/O Concurrency”:

To summarize the idea behind this enhancement:
Lucene is not concurrent inside: e.g. full of regular for-loops over data structures. Such loops are CPU efficient, but not always IO efficient because they’re sequential.
Let’s introduce an IndexInput.prefetch method: it hints to the underlying Directory implementation which parts of the data we are going to read really soon, so it can start prefetching in the background.
This will dramatically improve the situation for the HNSW search over S3Directory:

This makes all neighbor lookups parallel instead of being sequential! Since Lucene uses M=16 as the default value for its HNSW implementation, then we need only N=num_layers hops to S3 (in practice in the range of 3–5) instead of N*M=num_layers*num_neighbors!
Since S3 has not-so-nice latency but almost unlimited concurrency, this can improve the situation a lot:

So in practice you can reach a 1.1 GB/s S3-EC2 throughput even on low-cost EC2 instances with just 16 concurrent requests, maxing out the default 10 Gbps network adapter.
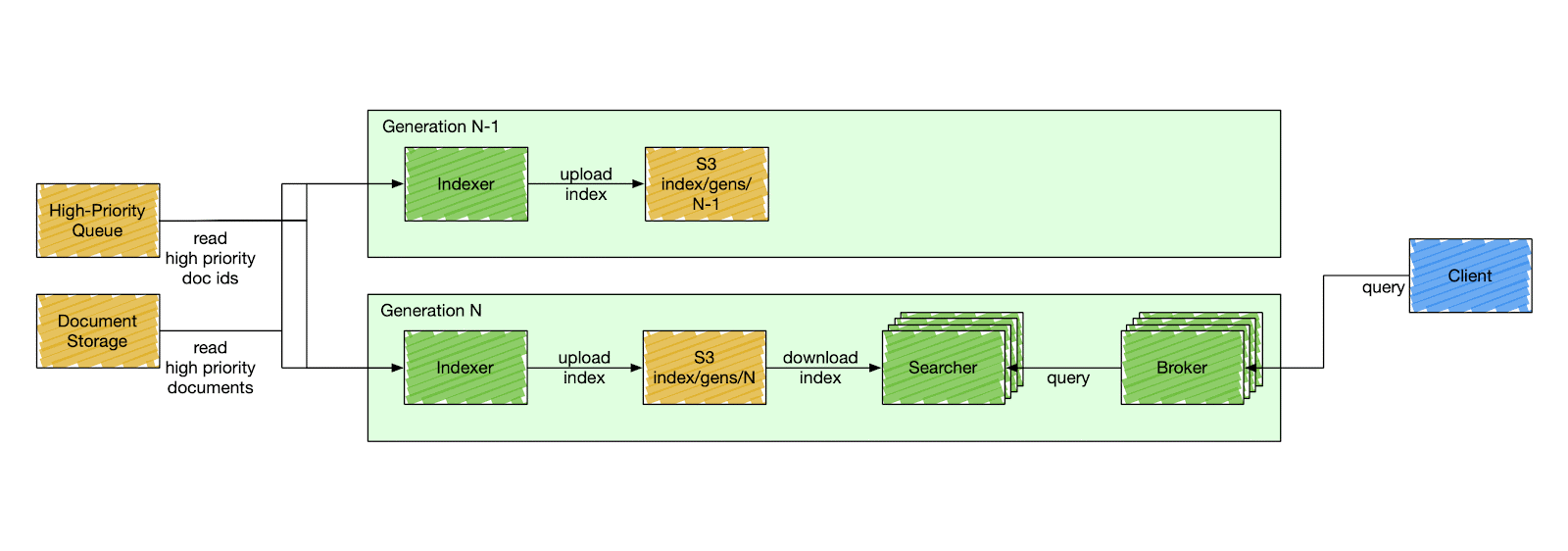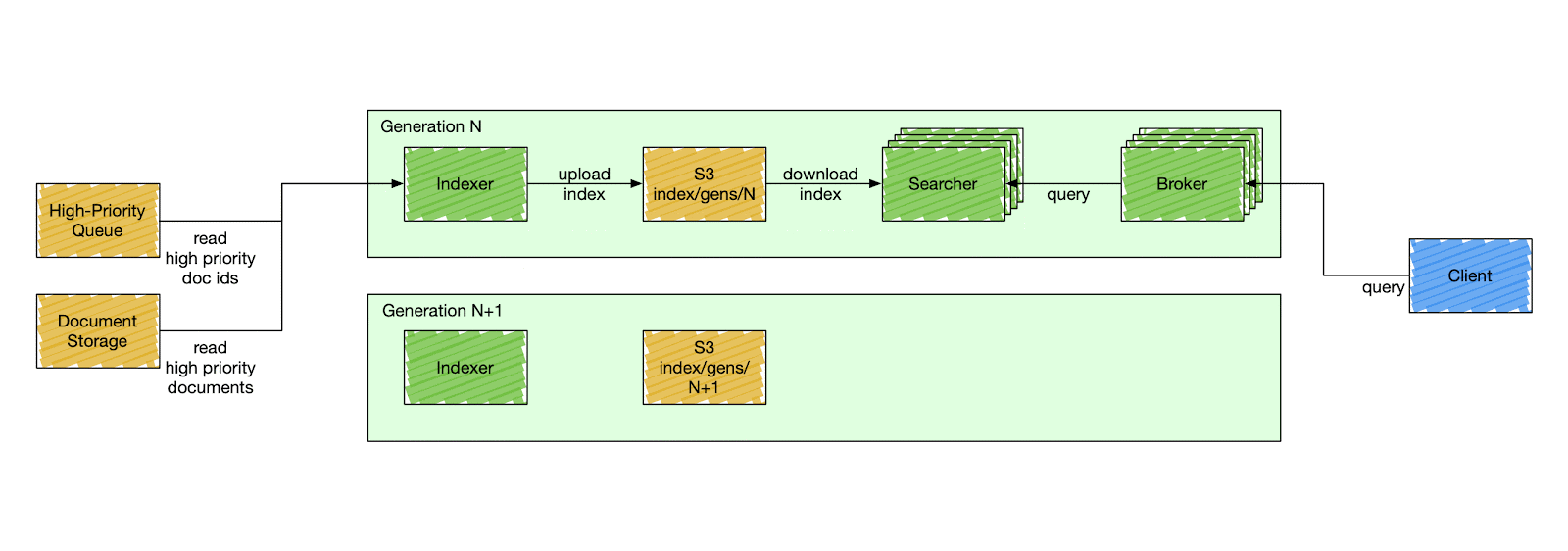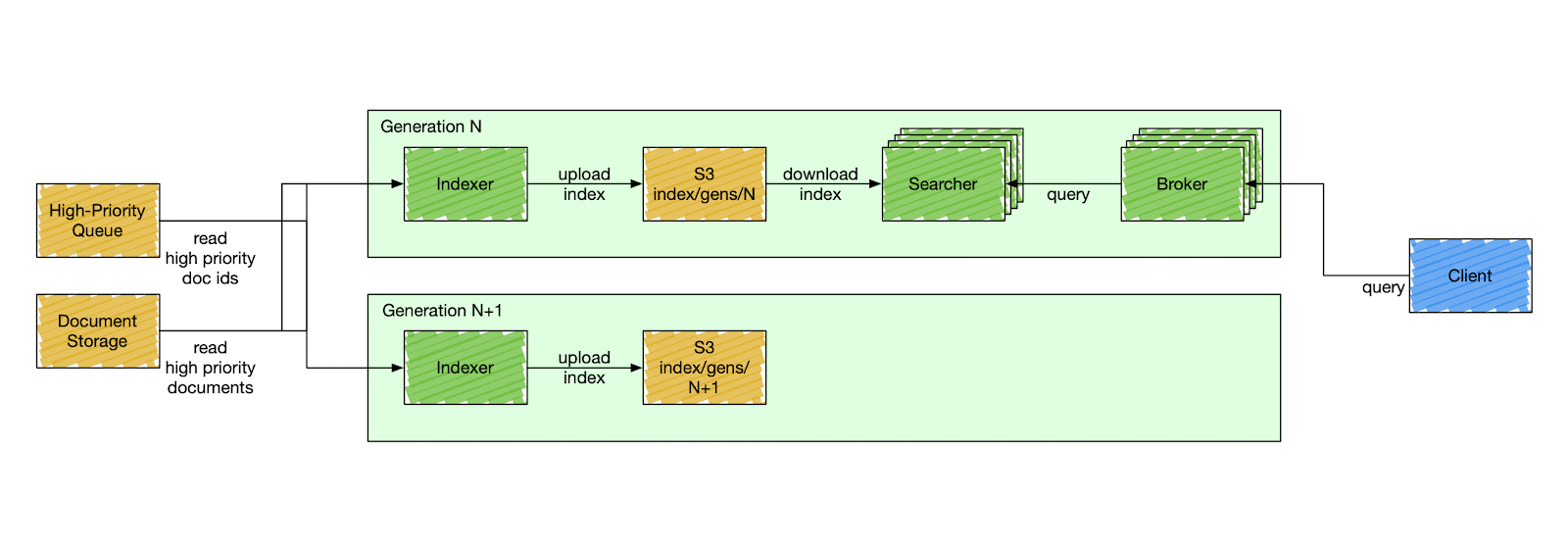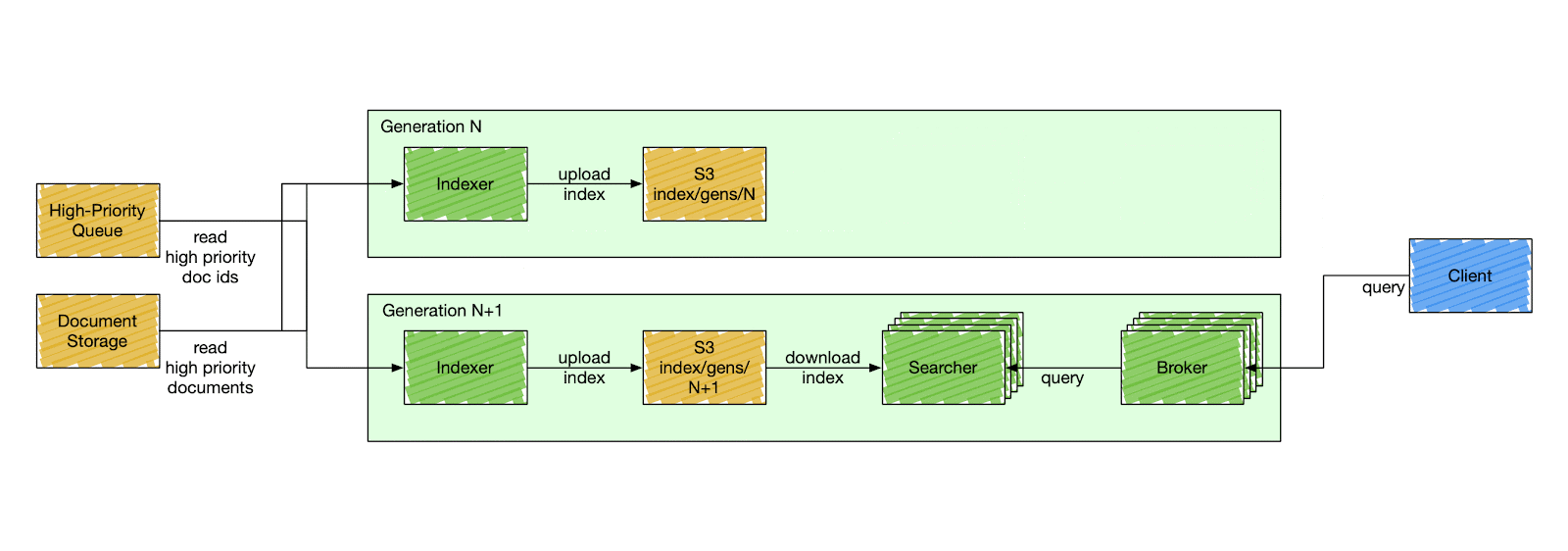
For Nixiesearch the Lucene 10 approach looks promising and we plan to re-evaluate the numbers when the LUCENE-13179 will get implemented. But as for now, Nixiesearch is using a more traditional segment-based replication approach:

How far can you go with stateless?
Segment-based replication is not a new thing and has been available in NRTSearch and OpenSearch for years. But the search nodes are still not stateless: there is index schema and cluster metadata that you can access and modify.
If you come from regular back-end app development, a regular deployment flow looks like this:
Commit to Git, make a PR.
PR gets reviewed, and later the CI/CD system takes care of rolling/blue-green deployment.
In contrast to this approach, to change an index configuration, you need to:
Send an HTTP POST request to a prod cluster. Pray.
Earth shakes, lights go on and off. You get a “hey wtf” Slack message from the CEO.
Can the index management be more like we do in a regular backend development?
Nixiesearch has no API to change runtime configuration, nor API to create and modify indexes. Everything is defined in a static config file that the server loads on startup:

In this snippet we:
define a “helloworld” index with two “title” and “price” fields
A title field has a text type, intended for semantic search, and uses the “text” model to perform the embedding process.
A price field is numeric and can be filtered, sorted and faceted over.
We also define an e5-small-v2 ONNX model for ML inference.
And after that we can send regular search queries:

But how can we change index settings if it’s immutable?
Changing things in Nixiesearch
Things are changed in Nixiesearch the same way as in traditional cloud deployment strategies by doing a rolling (or a blue-green) deployment. You never change the setup, you create a new one aside and gradually switch traffic when the new deployment reports an OK healthcheck.

Since search engine deployment depends not only on configuration, but also on an externally stored index in S3, Nixiesearch also validates if the configuration change is backward compatible and can use the same index.
If the change is backward compatible (e.g. change in caching settings), then the service reports OK to the readiness probe and starts accepting traffic.
If the change is incompatible and requires reindexing, then the readiness probe is not going to be OK until you reindex.
But since the entire index is just one directory on S3, reindexing is not as complicated as with traditional search engines.
Rethinking the reindexing process
Most of traditional search engines like Elastic/OpenSearch/Solr use push-based approach to indexing:
Submit a batch of document updates to the HTTP REST API of the prod cluster,
The cluster starts crunching the batch and updates the distributed index.
While this is a traditional approach, it still has a number of major drawbacks: you need to control the back-pressure (so the cluster won’t be overwhelmed with indexing) and the same nodes are used for searching and indexing (so your search latency will be affected).

But as the index is not anymore tied to the cluster, the whole reindexing process can happen offline:
With offline indexing, prior to starting the search cluster, you run a separate batch task to rebuild the index and publish it to S3 into a separate location. And then perform a rolling deployment as usual.
But does the design decision to have stateless searchers have any drawbacks?
[Lack of] Sharding
Stateless searcher architecture also assumes that searchers don’t talk to each other, as otherwise they’re no longer stateless. And sharding is an example of a feature that cannot be easily implemented on top of a stateless architecture.
This does not mean that there will be no sharding support in the future. We just accept the fact that we still do not yet know the best way to implement it without breaking the promise of remaining stateless.
From another practical perspective, in a consumer-facing search (e.g. e-commerce and enterprise doc search) you rarely have datasets so large that you cannot do without sharding:
A 1M docs MSMARCO index we used for testing is just 3GB on disk. With int8 quantization it’ll be about 800MB.
Indexes of 1B/1T docs are usually seen in log/APM/trace search tasks, and Nixiesearch will definitely not going be the best solution for this.
Text in, text out, 100% local
On the way to better ops, Nixiesearch tries to have as few dependencies as possible. The same goes for internal ML embedding and LLM models. Besides simpler deployment, this has also the following advantages:
Latency: a CPU ONNX inference of the e5-base-v2 model is about 5 ms. This is much faster than sending a network request to an external SaaS embedding API.
Privacy: your private data (i.e. documents and queries) does not leave your secure perimeter.

As of v0.3.0, Nixiesearch supports the following model families:
For a vector search, any ONNX-compatible sentence-transformers model should work. The model translation can be done either with Huggingface optimum-cli, or with an in-house onnx-convert tool (which can also perform model quantization).
For RAG, any GGUF model that works with llama-cpp should be compatible.
Of course, you can optionally use SaaS-based embedding and completion models from Cohere, Google, Mixedbread and OpenAI.
Furthermore, both indexing and serving services can be run on the GPU:
docker run --gpus=all nixiesearch/nixiesearch:0.3.3-amd64-gpu index Roadmap: reranking support
With ONNX model support for both CPU and GPU inference, an obvious next step would be to implement reranking support:
Since reranking is part of the common retrieval pipeline, we can then:
Retrieve the top-N (N=100) documents with hybrid search by combining lexical and semantic retrieval with RRF — Reciprocal Rank Fusion.
Rerank all found documents using a more advanced Cross-Encoder model, such as BAAI/bge-reranker-v2-m3.
Summarize the top-M (M=10) most relevant documents wusing the RAG approach.
Everything is done with local inference, no data left the searcher node.
Roadmap: ingestion pipeline
A common pain point of existing search engines is the need for a complicated ML-driven indexing pipeline to compute custom embeddings, do text processing and so on. Can we automate most of the typical ones?
We see such a pipeline becoming less of a separate application, but more of a feature of the engine itself:

The plan is to introduce a multi-modal search with CLIP-like models — but with the embedding and search process handled completely transparently by the engine itself.
We also plan to introduce an LLM-driven DSL for text transformation: so you can handle summarization and classification tasks (e.g. “does this doc belong to category A?”).
Yes, such an approach will require GPU for indexing, but since indexing can be a one-time task, it does not require a GPU powered node running for 24x365. And low-end GPU nodes are not that expensive these days: EC2 g4.large with Nvidia T40 GPU is ~$300/month.
Expect a bumpy ride
Nixiesearch is an actively developed project with many rough edges. Some features may be missing. Docs are imperfect — but they do exist!

And there will definitely be breaking changes in both configuration and index format. But with every Github issue you submit, it’s going to be more and more stable.
For the current v0.3.3, Nixiesearch can already do quite a lot of things:
Segment based replication over the S3-compatible block storage.
Filters, facets, sorting and autocomplete.
Semantic and hybrid retrieval.
RAG and local ML inference.
If you want to know more, here are the links:
Github: nixiesearch/nixiesearch (only 78 stars so far at the moment of publication)
Docs microsite: nixiesearch.ai
Slack: nixiesearch.ai/slack
Regarding sharding, I think that one reason people use them, concurrent retrieval and ranking, can be mitigated by using a concurrent searcher that uses parallel processing of segments. This parallelism of course is limited to the number of available CPU cores on a given node, but to most folks that should be enough. I'm not up to date and I don't know if Lucene has that already, but I remember AWS people discussed it few years ago. The problem with segments is that they are heavily unbalanced in size.
Another reason for sharding I think is indexing throughput. There, some form of partitioning of the input might be needed to some folks.
Amazing post!